
文字コードの考え方から理解するUnicodeとUTF-8の違い
UnicodeとUTF-8の違いを理解していない方が結構居るようなので、文字コードの考え方を元に解説してみようと思う。
文字コードとは何か?
文字コードとは、コンピュータ上で文字を扱うために、文字に対して割り当てられた数値のことであり、文字と数値の対応付けと呼べる。
この対応付けの種類は沢山あって、Shift-JISであったり、UTF-8であったりする。
以上!と言いたいけど、文字コードはこんなに単純ではない。文字コードを複雑にする要素は沢山あるが、今回の記事ではUnicodeとUTF-8の違いに焦点を絞って解説してみたいと思う。
文字コードの構成要素
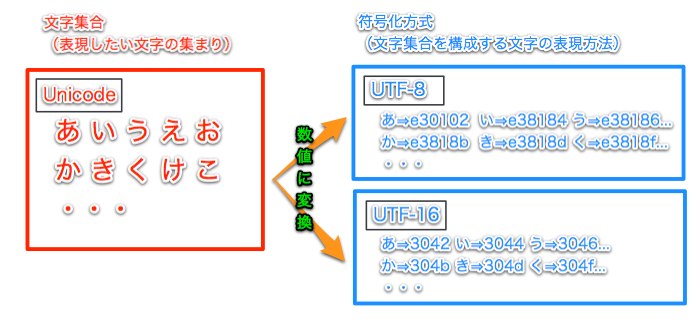
文字コードの世界は以下の2つの要素で構成されている。 この違いを意識しておかないと混乱を招くだろう。
(2).符号化方式 – 文字集合を構成する個々の文字の表現方法(数値の振り方)
世界中には日本語や英語、ドイツ語、中国語・・・など、大量の文字が存在する。これらの文字から表現したい文字の範囲(集合体)を定義する。これが(1)の文字集合だ。
次に(1)の個々の文字をコンピュータ上でどういった数値で表現するかを定義する。この数値の振り方が符号化方式(2)である。コンピュータはこの(2)で割り当てられた数値を用いて文字を表現する。
この文字集合と符号化方式を混合している方がよく居るが、この2つの考え方を理解すればUnicodeとUTF-8の違いも分かるだろう。
つまり
Unicodeは文字集合(1)であり、UTF-8は符号化方式(2)なのだ。
同じようにUnicode用の符号化方式としてUTF-16やUTF-32が存在する。
これらはUnicode文字集合に対する数値の振り方こそ違うものの、同じ文字集合から作られているから、表現できる文字の種類は同じなのだ。
なぜUnicodeとUTF-8を混合してしまうのか?
そもそも文字コードに興味の無い人が多くて、UTF-8はUnicodeの一部ような、ぼんやりしたイメージしか持っていない人が多い。強いて言うなら以下の2つだと思う。
Unicodeを符号化方式として扱っているソフトウェアの存在
よくネタとして挙がるのがWindowsのメモ帳。ファイルを保存する場合、以下の文字コードを選択できる。UTF-8の他に「Unicode」と「Unicode big endian」なるコードも選べてしまう。
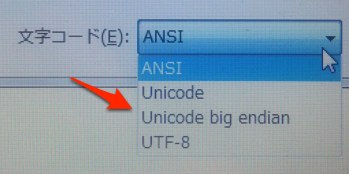
この表示、文字集合と符号化方式について理解していても混乱してしまう。
Unicodeって文字集合だよね??
符号化方式ではないのにファイル保存の形式に選べるってどういうこと??
実はWindowsのメモ帳でUnicodeを選択した場合の符号化方式は「UTF-16」と決められている。
「Unicode」と「Unicode big endian」は同じUTF-16だがエンディアンが異なる。
参考 – エンディアンとは
エンディアンとは複数バイトで構成されるデータの並べ方の事で、ビッグエンディアンとリトルエンディアンがある。例えば「0xABCD」という、2バイトのデータがあったとき、これを「ABCD」と並べるか「CDAB」と並べるかが異なる。前者がビッグエンディアン、後者がリトルエンディアンである。人の目から見ると「ABCD」の方が分かりやすいけど、コンピュータ視点で見ると「CDAB」の方が操作しやすい。
(計算は下の桁から始めるから、下位バイトが先に読み込めた方がコンピュータ的には都合が良い。人には見にくいけど)
試してみた。
Windowsのメモ帳でUnicode、Unicode big endian、UTF-8で保存したファイルをそれぞれ用意。
ファイル内の文字はすべて同じ。
$ ls Unicode.txt UnicodeBigEndian.txt utf-8.txt $ cat utf-8.txt あいうえお 一二三四五
まず、文字コードの確認
$ nkf --guess utf-8.txt UTF-8 (CRLF) $ nkf --guess Unicode.txt UTF-16 (CRLF) $ nkf --guess UnicodeBigEndian.txt UTF-16 (CRLF)
やはり「Unicode.txt」、「UnicodeBigEndian.txt」は両方ともUTF-16みたいだ。
ついでにエンディアンも確認
<2015/2/13 – 下記、エンディアンの判別方法を修正しました。リトルエンディアン・ビッグエンディアンの記載が逆となっておりました。>
今回はodコマンドを利用してファイルのバイナリ表現を出力する。odコマンドはエンディアンに依存した出力を行うため、1バイト単位で区切って出力するために-t x1オプションを付与して実行する。
(今回の環境はリトルエンディアン環境のため、-t x1を付与しないとリトルエンディアンを意識した出力(前後逆にする)となってしまう。)
$ od -t x1 Unicode.txt 0000000 ff fe 42 30 44 30 46 30 48 30 4a 30 0d 00 0a 00 0000020 00 4e 8c 4e 09 4e db 56 94 4e $ od -t x1 UnicodeBigEndian.txt 0000000 fe ff 30 42 30 44 30 46 30 48 30 4a 00 0d 00 0a 0000020 4e 00 4e 8c 4e 09 56 db 4e 94
やはり「Unicode.txt」はリトルエンディアンで、「UnicodeBigEndian」はビッグエンディアンだ。
ちなみに、エンディアンはファイルの先頭2バイトで確認できる。
この2バイトの事をBOM(ByteOrderMark)といい、エンディアンの判別に利用される。
(BOMが付与されていない場合はビッグエンディアンとして扱われる)
BOMが
「fffe」の場合:リトルエンディアン
「feff」の場合:ビッグエンディアン
と判別できる。
コードポイントが紛らわしい
文字集合にはコードポイントという符号化方式とは異なる数値の振り方がある。
コードポイントとは?
文字集合では、個々の文字に対して、文字集合内での符号位置が決められている。これをコードポイントという。
言い方を変えると、「文字集合を構成する文字を並べて、頭から順番に振った数値」のことだ。
このコードポイントはあくまで”その文字の文字集合内での位置”であり、符号化方式ではない。
例えば「ほげふが」のUnicodeのコードポイントは以下の通りである。
| 文字 | コードポイント |
|---|---|
| ほ | U+307B |
| げ | U+3052 |
| ふ | U+3075 |
| が | U+304C |
このU+XXXXはただの符号位置を表す数値なので、この値でデータを保存しても意味が無い。
文字を表現したい場合はコードポイントではなく、符号化されたByte列を用いる必要があるのだ。
このコードポイント、ぱっと見で符号化方式に見えてしまう。この点を理解していない方は混乱すると思う。
コードポイントの利用場面
コードポイントは様々な場面で利用されている。例えばJavaのプロパティファイル(.propertiesファイル)に日本語を記述する場合などだ。
Javaのプロパティファイルは文字コード「ISO-8859-1」で記述するというルールがある。
「ISO-8859-1」はほとんどASCII文字しか扱えなから、表現したい文字のUnicodeコードポイントをプロパティファイルに記述する。
例えば、「message=こんにちは」といったプロパティを定義する場合、
message=\u3053\u3093\u306B\u3061\u306F
と定義する必要がある。
\uは後続の文字がコードポイントを表していることを指し、その後ろにコードポイントを記載する。コードポイントの指す文字は「こんにちは」であるが、コードポイント自体は数値とアルファベットでのみ構成されるため、「ISO-8859-1」でも問題無く保存できるという訳だ。
この文字からコードポイントへの変換は通常IDEが自動的に実施するが、ファイルの実体はUnicodeコードポイントで表現されている。
また、「native2ascii」を使えばファイル内の「ISO-8859-1」が表現できない文字を手動でUnicodeコードポイントに変換できる。
※ ちなみに、J2SE 5.0からはxml形式のプロパティファイルを扱えるようになり、これをを利用すれば自由に文字コード指定できるようになった。
これ以外にもUnicodeコードポイントを利用する例は多々あるが、コードポイントは符号位置(文字集合内の文字の位置)であって、符号化方式ではない。そのためコードポイントはUnicodeの符号化方式であるUTF-8やUTF-16とは直接は関係しない。
簡単だけど、文字集合と符号化文字をまとめてみた。
文字コード関連では他にも色々とおもしろいネタがあるので、今後も時間を見て書いていくことにする。
関連記事
-

-
Ctrl+Cとkill -SIGINTの違いからLinuxプロセスグループを理解する
しばらくLinuxネタが続く・・。 近いうちに最近出たJava8ネタを書いてみようと思います。が、
-
-
「Systemd」を理解する ーシステム起動編ー
2014年6月10日、とうとうRHEL7が正式リリースを迎えた。RHEL7での変更点については、この
-
-
「Systemd」を理解する ーシステム管理編ー
前回の記事「Systemd」を理解するーシステム起動編ーでは、Systemdの概念とSystemdに
-
-
Linuxプロセス起動時の環境変数ダンプの取得
UnixやLinux上で不具合の調査等々を行う際、特定のプロセス起動時の環境変数を知りたい場合がある
-
-
sshd再起動時にssh接続が継続する動作について
Linux/Unixサーバにsshしている際、sshdを再起動したとする。 sshdは一度終了する
-
-
Java8のHotSpotVMからPermanent領域が消えた理由とその影響
今回も前回の記事につづき、Java8による変更点で未だあまり紹介されていないポイントを記事にしようと
-
-
Java8のインタフェース実装から多重継承とMixinを考える
2014年3月18日、ついにJava8が正式にリリースを迎えた。 折角なので、今後、Java8の新
-
-
ipsetを使ってスマートにiptablesを設定する
ギークな知人から「vpsでiptables設定していたらルール設定数の上限に引っかかって思い通りの設
-
-
例示専用のIPアドレスとドメインを使いこなす
前回の記事ではネットワークに関する記事を投稿させていただいたが、今回も引き続きネットワーク関連のネタ
Comment
Enjoyed the images, i truly like the one of %image_title%, perfect.
my website – http://journal-cinema.org/
はじめまして、文字化け問題を検索していてたどり着きました。
WordPressを使用しており、テーブル作成が簡単に行えるTablePressというプラグインを導入しました。
csvファイルを読み込んでテーブルを作ることもできるそうなので、試してみたところ文字化けが起こって困っていました。
多くの人はUTF-8(BOM)なしで解決できているそうなのですが、私の場合解決に至らず困っていました。
文字化けの仕方がこの記事に書かれている「u」から始まる英数字でした。
“テスト”と入力すると”u30c6u30b9u30c8″となってしまいます。
こういった場合はまずどこを疑えば良いべきなのでしょうか・・・。教えていただけませんでしょうか。
「Unicode.txt」と「UnicodeBigEndian.txt」の結果が逆になってませんか?
> feff 3042 3044 3046 3048 304a
はUTF-16 Big Endianで
> fffe 4230 4430 4630 4830 4a30
はUTF-16 Little Endianだと思うのですが。
> BOMが
> 「feff」の場合:リトルエンディアン
> 「fffe」の場合:ビッグエンディアン
> と判別できる。
これも逆だと思います。
バイトオーダーマーク – Wikipedia
http://ja.wikipedia.org/wiki/%E3%83%90%E3%82%A4%E3%83%88%E3%82%AA%E3%83%BC%E3%83%80%E3%83%BC%E3%83%9E%E3%83%BC%E3%82%AF
>しのぶ様
コメントありがとうございます。内容確認しました。
ご指摘の通りリトルエンディアンとビッグエンディアンの記載が逆となっておりました。
失礼しました。記事の内容は修正しております。
なお、記事中でファイルのバイナリ表現の取得にodコマンドを利用しておりましたが、odコマンドはエンディアン依存の出力を行うため、筆者のリトルエンディアン環境では、前後逆表記となったバイナリ表現が出力された状態(実際のファイル内容とは異なるバイナリ表現)となっておりました。
odコマンドに-t x1オプションを指定し、1バイト単位でのバイナリ表現を取得することでエンディアンの置き換えが行われないよう記事は修正しております。(併せてエンディアンの判別部分も記載を修正しております)
今回はご指摘いただきありがとうございました。
文章がわかりやすく大変参考になりました
>符号化方式(文字集合を構成する文字の表現方法)
の画像の中の「UTF-8」の「あ」の文字コードは
「e38182」ではないでしょうか
大変参考になりました
[…] >>Unicodeは文字集合(1)であり、UTF-8は符号化方式(2)なのだ。 http://equj65.net/tech/charcode/ […]
参考になりました
とても参考になりました!
IT業界で働いて5年目にして初めてしりました(笑)
ありがとうございます!!
やっとユニコードが何なのかわかりました
ありがとうございます
Apicerpation for this information is over 9000-thank you!
UnicodeはUnicode consortiumが定義した符号化文字集合及び文字符号化スキームを含む規格の総称であり、符号化文字集合(ご記事にある「Unicode」)はUCS(Universal Character Set)で、UTF-8は“Unicode Transformation Format-8”の略で文字符号化スキームのうちの1つであると理解していました。よってUnicodeはUCSとUTF-8を両方を含むと…。
コードポイントの利用例、これコードポイントじゃなくてUTF-8とかの符号を直接書いちゃだめなのかな?
ex) \u3053\u3093\u306B\u3061\u306F
ではなく
e30182e38184…
みたいな
それだとただの文字列になってしまいます
「コードポイントの利用場面」が間違ってますよ。
# Javaのプロパティファイル(.propertiesファイル)に日本語を記述する場合などだ。
とありますが、実際にはコードポイントを直接利用することなんてまずありません。プロパティファイルに記述する値はコードポイントではなく、UTF-16のコード値です。Javaなんですから。
これではあなたが『「UnicodeとUTF-16」もしくは「文字集合と符号化方式」の違いを理解していない人』ということになってしまいますよ。
BPMしかなかった頃に限って言えば、コードポイントとUTF-16のコード値は一致しており、正しいと言えましたが、UnicodeがBPM以外にも拡張されたのは2001年です。それ以降は、コードポイントとUTF-16のコード値を区別する必要ができました。
符号化方式をちゃんと説明してないから、わからない言葉をわからない言葉で説明している状態になって、さっぱりわからない でもとっかかりにはなった
わかりやすかったです。
ありがとうございます。
さっぱりわからん
「文字を表現したい場合はコードポイントではなくバイト列を使う必要がある」
と書いた次の段落でコードポイント使って文字を表現してるし何が言いたいのかさっぱりわからん
文字化けについて考えていました
すっきり腑に落ちました,有難うございます。
Very cool! I really like the content, good information and good news like this. 文字 と ー ド の 考 え 方 か ら 理解 す す Unicode と UTF-8 の 違 い
Hello, everybody,
I’ve got good news, I found some fresh original adult content! I think it’s “Adult Netflix”. There’s an Naked News tube here!
Looking for scenes from similar TV shows? Although, I found almost all new adult movies and series on this site!
Thx
This is a great inspiration.
pls visited my website herepussy888
文字 と ー ド の 考 え 方 か ら 理解 す す Unicode と UTF-8 の 違 い
918kiss เล่นก็ง่ายได้เงินจริง แจกจริง การันตีด้วยลูกค้าที่เพิ่มขึ้นอย่างต่อเนื่อง ประสบการณ์ที่มีมามากว่า 10 ปี ทำให้ 918kiss กลายเป็นเว็บสล็อตออนไลน์อันดับ 1 ในเวลานี้ สมัครเลยอย่าช้า 918kiss เท่านั้น
918kissนอกจากจะคลายเครียดได้แล้วท่านยังมีโอกาสที่จะมีรายได้ง่าย ๆ จากการเล่นสล็อตออนไลน์ก็เป็นได้ ด้วยโบนัส แจ็คพ็อต ที่แตกแจกจริง แจกบ่อย ราวกับการลดราคาสินค้าแบบกระหน่ำซัมเมอร์เซลแล้ว ท่านยังจะได้รับ ประสบการณ์ที่ยอดเยี่ยม
918kissติดต่อ เราได้ ที่ @918sc แอดไลน์มาเลย อย่าลืม ใส่ @ ด้วยนะ
เรามีพนักงานไว้บริการท่าน ตลอด สมัคร ฝาก ถอน หรือสอบถามปัญหาต่างๆ ได้ ไร้กังวล ทักปุ๊ป ตอบปั๊ป
918kiss สล็อตออนไลน์ อันดับ 1 ในเวลานี้อย่าง 918kiss มาได้เลย นอกจากจะคลายเครียดได้แล้วท่านยังมีโอกาสที่จะมีรายได้ง่าย ๆ
918kissthe best slot online no.1 in thai
918kissthe best slot online no.1 in thais
918kissthe best slot onlinesssno.1
918kissthe best slot online no.1 in thaissss
918kissthe best slot online no.1 in thaiws
918kiss thai slot online playnowsss
918kissthe best slot online no.1 in thaissasawe
918kiss thai slot online playnows
918kiss thai slot online playnow
918kissthe best slot online no.1sd
sbobet web online casino website providers football betting The new version supports SBO Mobilesd
918kiss thai slot online playnowdsdss
ballmunดูบอลสดบอลฟรี ดูบอลมันส์ดอทคอมเท่านั้น
918kiss thai slot online playnowssadwa
ดูบอลออนไลน์ดูบอลสดบอลฟรี ดูบอลมันส์ดอทคอมเท่านั้น
ดูบอลออนไลน์ดูบอลสดบอลฟรี ดูบอลมันส์ดอทคอมเท่านั้น
918kiss thai slot online playnowssdw
918kiss thai slot online playnowsddss
918kiss thai slot online playnowsssd
918kiss thai slot online playnowsss
918kiss thai slot online playnowsssdsadasd
918kiss thai slot online playnowssssssd
918kiss thai slot online playnowssdw
918kiss thai slot online playnowsawd
918kiss thai slot online playnowsadw
918kiss thai slot online playnowsdaws
918kiss thai slot online playnowsdws
918kiss thai slot online pหหหหหหหlaynow
918kiss thai slot online playnowsadaws
918kiss thai slot online playnowsadwsadg
918kiss thai slot online playnow real is real slotssdaas
918kiss thai slot online playnow real is real slotssadwav
918kiss thai slot online playnow real is real slotssdawx
918kiss thai slot online playnow real is real slotssdvfdsx
918kiss thai slot online playnow real is real slotssadwzxcv
918kiss thai slot online playnow real is real slotssadczzsdz
918kiss thai slot online playnow real is real slotssadwsac
918kiss thai slot online playnow real is real slotssadwxcxz
918kiss thai slot online playnow real is real slotsfhaerg
918kiss thai slot online playnow real is real slotserwdsfa
918kiss thai slot online playnow real is real slotsasdwxcz
918kiss thai slot online playnow real is real slotssdaweqedsdfafsczx
918kiss The professional company 918kiss
Online Casino FOR FUN!
Play for real money and FREE BIG BONUS every days.
AMBBET
เว็บเกมออนไลน์ที่กำลังมาแรงเป็นอันดับต้นๆในขณะนี้ที่ได้รับตวามนิยมมากที่สุดและจะช่วยส่งเสริมผู้เล่นทุกท่านที่ไม่มียอดทุนน้อยก็ตาม ทาง เข้า pg ผู้เล่นจะได้พบกับประสบการณ์การเล่นเกมออนไลน์รูปแบบใหม่ที่ได้ถูกพัฒนามาเป็นอย่างดีและสามารถสร้างรายได้อีกหนึ่งช่องทางได้จริง
ปัจจุบันเกมออนไลน์สามารถหาเงินได้จากการลงทุนซึ่งผู้เล่นสามารถเลือกลงทุนเท่าไหร่ก้ได้ไม่มีขั้นต่ำภายในเกมจะได้รับยอดหลายเท่าตามจำนวนลงทุน pg สล็อต สามารถสร้างรายได้อย่างมาหาศาลเป็นรูปแบบหาเงินที่ง่ายที่สุดและจะมารีวิวการเล่นที่หลากหลายรูปแบบให้ผู้เล่นมือใหม่
เกมสล็อตแตกง่าย ที่จะพาคุณเข้าไปท่องโลก ไปกับ Pgslot เว็บตรงด้วยระบบที่พิเศษของตัวเกม มีรูปแบบจัดทำออกมาให้เป็นเกมที่เล่นง่าย แจ็คพอต (Jackpock) แตกบ่อยที่สุด
power100 แทงบอลออนไลน์
You make so many great points here that I read your article a couple of times. Your views are in accordance with my own for the most part. This is great content for your readers
SLOTXO TRUE WALLET, the service we are proud to offer to provide convenience Facilitate our member players. With top-up, withdrawal, credit service for playing SLOTXO games
ร้านบุหรี่ไฟฟ้า siamks บุหรี่ไฟฟ้า Kardinal Stick คุณภาพดี ของแท้ 100% จากมาเลเซีย ตอบโจทย์ไลฟ์สไตลนักสูบเป็นอย่างดี ไม่ว่าจะเป็นเรื่องกลิ่น รูปลักษณ์ และราคา
Quik หนึ่งในนวัตกรรมจากทาง Kardinal stick ผลิตภัณฑ์ล่่าสุดแห่งปี 2023 ที่ได้นำเอาเทคโนโลยรสมัยใหม่อย่าง Mesh Coil ที่จะเป็นการติดตั้งใยเส้นฝ้ายออรืแกนิกที่มาพร้อมกับคอยล์ตาข่าย เพิ่มฟีลสูบและกลิ่นที่ชัดยิ่งกว่าเดิม
พอตบุหรี่ไฟฟ้า Ks Kurve มี 4 สีให้เลือก วัสดุภายนอกเรียบหรู มีความทนทานเกรดดีเยี่ยม และพาพร้อมกับเทคโนโลยีใหม่ fast charge ที่ชาร์จเพียง 18 นาทีก็สามารถเพลิดเพลินกับการสูบได้อย่างเต็มที่
เว็บพนันออนไลน์ Onlybets168
เล่น บาคาร่า แทงบอล สล๊อต หวย ครบวงจรง่ายๆ เพียงแค่มีมือถือเครื่องเดียวก็เล่นได้ ฝากถอนขั้นต่ำ 1 บาท มีทีมงานบริการ 24 ชม. ลองเลยแล้วคุณจะไม่ผิดหวัง
Ks Quik 800 บุหรี่ไฟฟ้าแบบใช้แล้วทิ้งรุ่นใหม่ ง่ายต่อการใช้งานเพียงแค่แกะซองก็พร้อมใช้งานได้ทันที โดยไม่ต้องกดปุ่มใดๆทั้งสิ้น ยกระดับการสูบให้มากถึง 800 คำ ให้คุณใช้งานได้อย่างยาวนานมากขึ้น
ทดลองเล่นสล็อตแตกง่าย สล็อตทุนน้อย แตกจริง เล่นสล็อตฟรี เล่นสล็อตฟรี ไม่ต้องสมัคร เล่นฟรีทุกค่าย ทดลองเล่นสล็อตPG ใหม่ล่าสุดก่อนใคร เว็บสล็อตอันดับหนึ่งในไทย
เว็บสล็อตใหม่ล่าสุด 2023 tgabet auto แหล่งรวมเกมสล็อตค่ายใหม่ มาแรง ทำเงินง่าย ถอนได้จริง โปรโมชั่นมากมาย ฝาก50รับ100 หรือ ฝาก100รับ200
Disposable pods Ks Quik 800 are economical, but can fill you up to 800 times. Comfortable, reducing the problem of liquid leakage
บุหรี่ไฟฟ้า เป็นวิธีที่น่าสนใจและนวัตกรรมในการเสนอทางเลือกที่ดีกว่าในการสูบบุหรี่แบบดั้งเดิม ด้วยการรวมเอาเทคโนโลยีที่ทันสมัย การออกแบบที่สวยงาม และประสิทธิภาพที่ยอดเยี่ยม บุหรี่ไฟฟ้านำเสนอประสบการณ์การสูบที่ไม่เหมือนใครสำหรับผู้ใช้ในทุกระดับ พร้อมกับความหลากหลายของรสชาติ
พอต เปิดโอกาสสู่การสูบที่ดียิ่งขึ้นและนวัตกรรมในการเสนอทางเลือกที่ดีกว่าในการสูบบุหรี่แบบดั้งเดิม ด้วยการผสมผสานเทคโนโลยีที่ทันสมัย การออกแบบที่ประหยัดพื้นที่และประสิทธิภาพที่โดดเด่น พอตนำเสนอประสบการณ์การสูบที่ไม่เหมือนใครสำหรับผู้ใช้ทุกเพศและวัย
บุหรี่ไฟฟ้า podcafe จำหน่ายบุหรี่ไฟฟ้า พอตไฟฟ้า แบรนด์ชั้นนำ มาตรฐานระดับสากล ของแท้ 100% เช่น Kardinal stick , Relx , Infy มีสินค้าให้เลือกมากมาย พร้อมให้คำแนะนำ ก่อน หลัง บริการ แอดมินตอบแชทไว 24ชม.
พอต ไฟฟ้า สุดปัง เพื่ออนาคตที่ดีกว่า เลิกบุหรี่แบบเดิมได้ง่ายขึ้น ด้วย พอตไฟฟ้า ไม่ทรมาน ได้รับนิโคติน สามารถลดปริมาณนิโคติน จนเลิกใช้นิโคตินได้ในที่สุด ไม่มีสารก่อมะเร็ง กลิ่นหอม ไม่มีกลิ่นเผาไหม้ ใช้งานง่าย ราคาประหยัด
pod vaping has gained immense popularity due to its convenience, portability, and flavorful experience. The compact design, ease of use, and wide range of flavors make it a preferred choice for vapers seeking a hassle-free vaping experience. Embrace the world of pod vaping and enjoy a convenient and satisfying way to indulge in your favorite flavors wherever you go.
Infy pod entry into the vaping industry is set to bring about a significant shift. Their commitment to safety, personalization, and sustainability offers a fresh take on e-cigarettes and has the potential to redefine vaping standards globally.
เราคือเว็บคาสิโนอันดับ 1 ที่ได้รับความนิยมสูงสุด ให้บริการมาอย่างยาวนานที่สุด. จีคลับ888 เครดิตฟรี เป็นแหล่งรวมเกมเดิมพัน คาสิโนออนไลน์ แบบครบวงจร สมาชิกทุกท่าน สามารถเล่นเกมเดิมพันผ่านมือถือ ได้ทุกที่ ทุกเวลา
awv7cz
Pedia4D menjadi situs agen slot online resmi yang bekerjasama dengan provider terbaik di dunia. Anda dapat memainkan permainan fantastis ini bersama kami sebagai tempat bermain judi slot paling gacor https://loginpedia4d.com/
Infy บุหรี่ไฟฟ้า น้องใหม่ มาแรง ใช้งานง่าย พร้อมดีไซน์หัวน้ำยาแบบใส สามารถมองเห็นปริมาณของน้ำยาได้เลย ตัวพอตออกแบบมาให้มีสีสันทูโทน หลากหลายสี สามารถเลือกได้เข้ากับสไตล์ของคุณ ตกแต่งด้วยไฟ LED สุดชิค
Infy รุ่นใหม่2023 พอตไฟฟ้าแบบมีไฟ LED สุดสะดวก สามารถใช้หัวน้ำยาร่วมกับ Relx infinity และ Relx Phantom ได้ พกพาสะดวก มีตัวเครื่องให้เลือกถึง 6 สี ดีไซน์ของหัวพอตแบบใส โดดเด่น พร้อมไฟ LED ลูกเล่นสุดเก๋ พร้อมสามารถมองเห็นปริมาณน้ำยาได้อย่างชัดเจน
Creating a successful online gambling website requires a combination of careful planning, legal adherence, technical expertise, and a commitment to providing an enjoyable and safe gaming experience. รับทำเว็บพนัน By conducting thorough market research, partnering with reliable software providers, and prioritizing user satisfaction, you can enter the competitive world of online gambling and establish a platform that stands out in the industry. Remember, success in this field hinges on your ability to adapt to changes, innovate, and always put the player’s well-being first.
พอต Infy , vaping stands as a more environmentally friendly choice compared to traditional smoking. Infy integrates this green philosophy by providing rechargeable devices, which significantly reduces waste associated with disposable cigarettes, thereby contributing to a healthier planet.
Choose a diverse and enticing selection of slot games. รับทำเว็บพนัน Work with reputable game providers to ensure quality and fairness.
ผู้ให้บริการเกมคาสิโน yehyehคาสิโน ที่ได้มาตรฐานระดับสากลเป็นเกมที่เข้าถึงง่าย เล่นสนุกเดิมพันต่ำ แต่ได้เงินสูง
“I would like to invite you to join this website
senopatibola“” thanks”
SBO Parlay is a mobile version of the online soccer game site with the best quality that provides victory for players
Bisnistoto pelajaran hidup.
የጣፊያ ትራንስፕላንት የባንኮች ማጠቃለያ የሆነው ወይም በስኬት የተመከረው መጠን የሚሆነው አንድ ነው። በአንድ ውሂብ እና በአንድ የተከለከለው በሀገራት የሚኖረው ውሂብ የሚጠቀም ለማስተዳደር ተራንስፕላንት እንደሚያደርግ ይመስላል። እነዚህን በርካታ የሚመከሩ የጣፊያ ትራንስፕላንት እውነተኛ አሰራር ይገኛሉ። እነዚህ በተግባር የተለያዩ የሚዘረጋውን የጣፊያ ትራንስፕላንት የሚከታተሉ የሚሆኑ እንደዚህ መሆን አለበት።
Rk-club ร้านบุหรี่ไฟฟ้า ที่ดีที่สุด บริการระดับพรีเมี่ยม ของแท้ทั้งร้านแน่นอน มีบริการก่อนและหลังการขาย ไม่ว่าจะเป็นลูกค้ามือใหม่ หรือมือเก๋า ก็สามารถรับโปรโมชั่นสุดพิเศษจาก RK-CLUB ได้
หากคุณเป็นสิงฆ์อมควัน ไม่มีทางที่จะไม่รู้จัก Marbo ตอนนี้ทาง Rk-club มีโปรโมชั่นดี ๆ ของ หัว marbo ราคาส่ง ถูกใจสายควัน ประหยัด ใช้งานได้ยาวนาน ที่สำคัญของแท้ 100% จัดส่งทั่วประเทศไทย สะดวกรวดเร็วรอรับหน้าบ้านได้เลย
የጣፊያ ትራንስፕላንት የባንኮች ማጠቃለያ የሆነው ወይም በስኬት የተመከረው መጠን የሚሆነው አንድ ነው። በአንድ ውሂብ እና በአንድ የተከለከለው በሀገራት የሚኖረው ውሂብ የሚጠቀም ለማስተዳደር ተራንስፕላንት እንደሚያደርግ ይመስላል። እነዚህን በርካታ የሚመከሩ የጣፊያ ትራንስፕላንት እውነተኛ አሰራር ይገኛሉ። እነዚህ በተግባር የተለያዩ የሚዘረጋውን የጣፊያ ትራንስፕላንት የሚከታተሉ የሚሆኑ እንደዚህ መሆን አለበት። ioi
https://www.ilivetocook.com/
https://www.griffonplaza.com/
https://www.coletivaocupacao.com/
https://www.burslemschoolofart.com/
https://www.bgbiznes.com/
https://www.nonprofitshoppingmall.com/
https://www.grootejonkvrouw.com/
https://www.cssetrain.com/
https://www.criminaljusticepapers.com/
https://www.nhmoves.org/
cabal red พาคุณเข้าสู่โลกแฟนตาซีที่เต็มไปด้วยปริศนาและความท้าทาย คุณจะได้สัมผัสการต่อสู้ที่รวดเร็ว เร้าใจ และเข้มข้นไปกับระบบ PvP สุดเร้าใจ สร้างสกิลที่เหมาะกับสไตล์การเล่นของคุณ และรวบรวมเพื่อนร่วมทีมเพื่อปกป้องดินแดนจากศัตรูที่มาโจมตี เตรียมตัวให้พร้อมสำหรับการต่อสู้ที่คุณไม่เคยพบเจอมาก่อน
Pretty good post. I have just stumbled upon your blog and enjoyed reading your blog posts very much. I am looking for new posts to get more precious info. Big thanks for the useful info.
Themes in Online Slot Games From ancient mythology to futuristic sci-fi, online slots come with various themes to suit every player’s interest. ezslot22
tga69 Progressive Jackpots Progressive jackpot slots offer massive prizes that increase with each spin until a lucky player hits the jackpot.
Hello, I am one of the most impressed people in your article. sòng bạc I’m very curious about how you write such a good article. Are you an expert on this subject? and good toto site info for you.
I visited last Monday, and in the meantime, I came back in anticipation that there might be other articles related to I know there is no regret and leave a comment. Your related articles are very good, keep going!!
A clear and concise explanation! Understanding character codes and the difference between Unicode and UTF-8 is essential for handling text in computing.
I am glad to read this post, it’s an impressive piece. I am always searching for quality posts and articles and this is what I found here, I hope you will be adding more in future.
Unicode と UTF‑8 の違いが整理されていて、とても分かりやすいです。実際のファイル例を交えて説明してくれるところが参考になりました.
解説が分かりやすく、UnicodeとUTF‑8の違いがはっきり理解できました。これからの文字コード選びに活かせそうです。